Intrinsic dimension estimation for robust detection of ai-generated texts
Eduard Tulchinskii, Kristian Kuznetsov, Laida Kushnareva, and 5 more authors
Advances in Neural Information Processing Systems, 2024

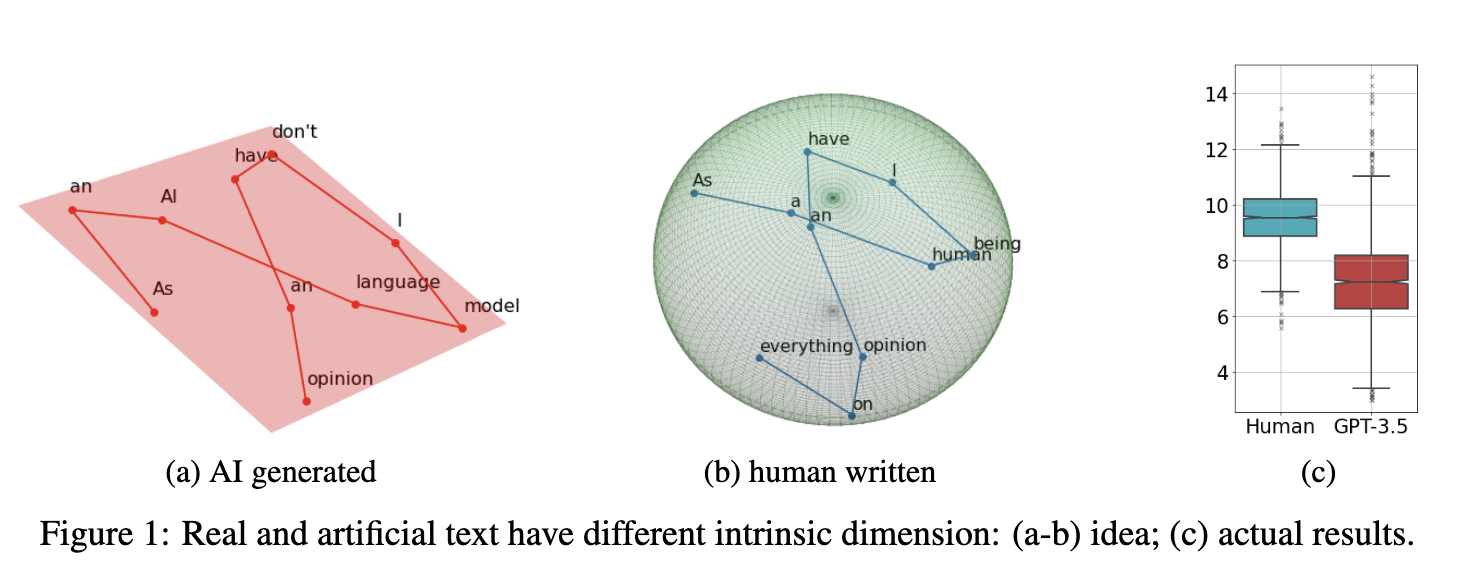
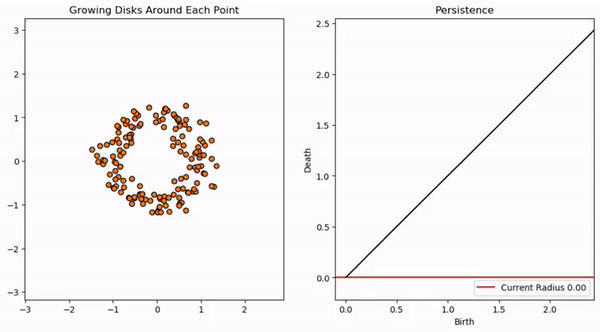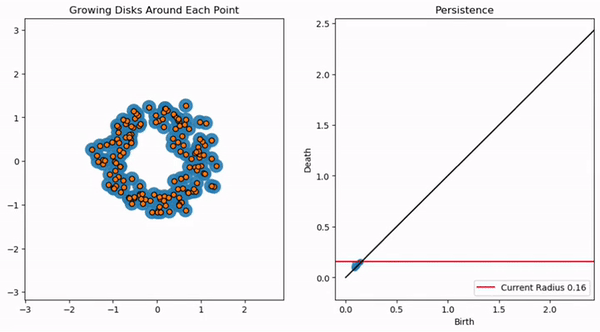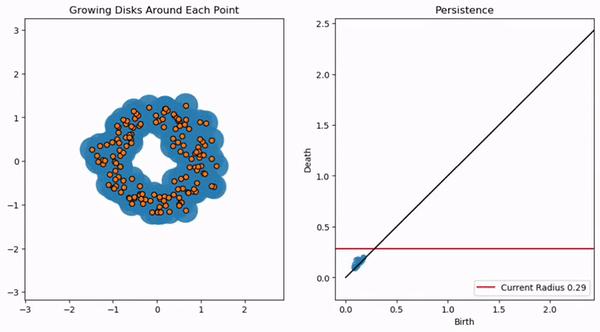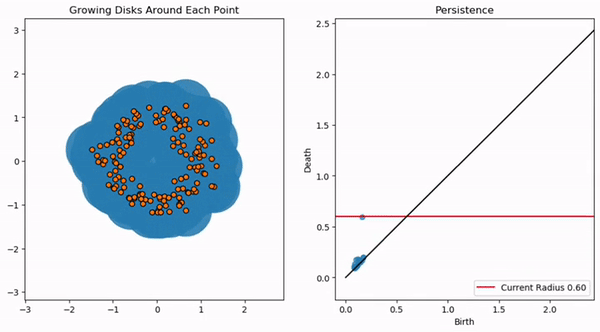
Rapidly increasing quality of AI-generated content makes it difficult to distinguish between human and AI-generated texts, which may lead to undesirable consequences for society. Therefore, it becomes increasingly important to study the properties of human texts that are invariant over different text domains and varying proficiency of human writers, can be easily calculated for any language, and can robustly separate natural and AI-generated texts regardless of the generation model and sampling method. In this work, we propose such an invariant for human-written texts, namely the intrinsic dimensionality of the manifold underlying the set of embeddings for a given text sample. We show that the average intrinsic dimensionality of fluent texts in a natural language is hovering around the value 9 for several alphabet-based languages and around 7 for Chinese, while the average intrinsic dimensionality of AI-generated texts for each language is ≈1.5 lower, with a clear statistical separation between human-generated and AI-generated distributions. This property allows us to build a score-based artificial text detector. The proposed detector’s accuracy is stable over text domains, generator models, and human writer proficiency levels, outperforming SOTA detectors in model-agnostic and cross-domain scenarios by a significant margin.